Up to the limits of my own patience, I hand-classified as many tweets from the April 20 broadcast of QandA as positive, negative (or spam), with the goal of using these to train a sentiment dictionary to use on the April 27 broadcast’s tweets. I also removed all retweets from the dataset (which I suppose I should have done in the previous post as well). There was a slight problem in the way I’d written the tweets to file and forgotten to remove the new-line characters within tweets, so my code was also reading all these irrelevant lines as separate tweets.
I came across a whole raft of issues as soon as I started this process. The main problem, as I stated in the previous post, is that a large proportion of tweets are too short to be able to be judged for their sentiment at all. A lot of them are irrelevant for my purposes of estimating the political leanings of Twitter users watching QandA because they represent conversations between users (e.g. “are you watching #QandA?”) rather than actual comment on the program and its contents and panel members.
I wrote a Python script to make the process of classifying the tweet data I had a little easier. Since the other portion of my code, the simple political entity classifier, should take care of whether the conversation is relevant or not, I can use all the tweets to train for sentiment data. Initially I hoped I would only need three classifications: positive, negative, or spam. There is obviously some subjectivity here, particularly with the short and often sarcastic nature of tweets, but hopefully the volume of data will take care of this. After looking at enough tweets I realised some tweets just cannot be classified as positive or negative and so we also need a neutral classification.
My training code is pretty simple, because all the real work is unfortunately with the human classifying the tweets:
import numpy as np
with open('tweetdump_new.txt') as f:
tweets = f.readlines()
classified_dict = {}
for tweet in tweets:
classified_dict[tweet] = False
tweets_total = len(classified_dict)
def main():
## Keep two files open: test_tweets.txt which contains the
## unclassified tweet data, and trained_tweets.txt which contains the
## classified tweet data.
with open('trained_tweets.txt', 'a') as g:
count = 0
for tweet in tweets:
print tweet
classification = raw_input('Classify this tweet as negative (0), positive (1), neutral(2) or spam (9): ')
g.write(tweet.replace(',','') + str(classification))
g.write('\n')
classified_dict[tweet] = True
print '-----------------------------------------------'
count = count + 1
if count%40 == 0:
print str(np.round(100*float(count)/float(tweets_total),2))+'% completed...'
print '-----------------------------------------------'
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
with open('test_tweets.txt', 'w') as f:
for tweet in classified_dict:
if classified_dict[tweet] == False:
f.write(tweet)
The code contains two small improvements on the most basic idea possible; a percentage completion counter for sanity purposes, which prints progress every forty tweets, and the ability to quit the program and pick up where you left off (it just writes all the unclassified tweets over the input file so you can start again with a smaller file).
One very difficult consideration is how to deal with sarcasm on the training set. Often words which you know should be assigned a positive sentiment score are being used sarcastically in a tweet that overall has a negative sentiment. I score these tweets as positive in the optimistic (and untested, and probably misguided) view that there is more genuine discussion on Twitter than sarcasm.
Some things I noticed doing this classification before I got bored and just used what I’d completed:
- a plurality of tweets are negative (the split between negative / positive / neutral is about 45/30/25).
- this process is bound to introduce a whole bunch of subjectivity.. hopefully my left-wing bias is not obvious
- classifying tweets is extremely difficult! Sometimes you can spend minutes agonizing over tweets deciding on their sentiment.
I classified 1000 tweets from the first broadcast, which gave me a corpus of over 3300 words with a sentiment score. It was then easy to get a crude sentiment score for each tweet from the second broadcast’s feed:
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
frame = pd.read_csv('SentimentDict.txt',skiprows=0,delim_whitespace=False,header=0,names=['term','rating'])
frame.index = frame['term']
with open('tweetdump27_new.txt') as f:
tweets = f.readlines()
def GetSentiment(tweet):
score = 0
for word in tweet.split(' '):
try:
score = score + frame['rating'][word]
except KeyError:
pass
return score
scores_list = []
for tweet in tweets:
if type(GetSentiment(tweet)) is np.int64:
scores_list.append(float(GetSentiment(tweet))/float(len(tweet)))
plt.hist(scores_list,bins = 50)
plt.show()
[Finished in 28.7s]
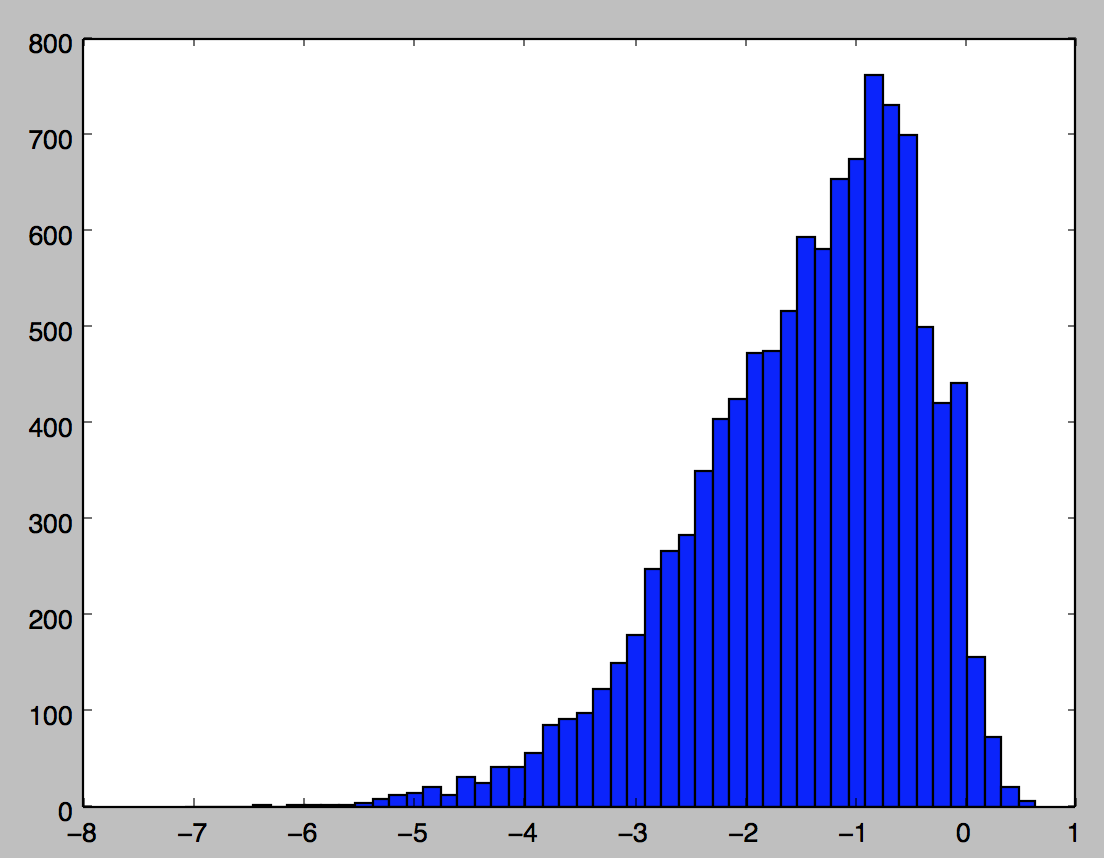
We can see the distribution of the (length-adjusted) sentiments very well in the above image (there’s 11 224 tweets being scored here, once I’ve taken out retweets and spam). Notice that less than 5% of tweets are actually assigned a positive score (since there’s so much negativity on Twitter, common words like “the” end up with highly negative scores by virtue of appearing in more negative tweets than positive).
Two things remain to do (noting that the analysis will only get better and more accurate the more tweets I classify):
- use the training data to come up with a decision boundary for tweets to be labelled as positive or negative
- add the basic left/right entity recognition into the analysis and try to answer my original question again