
If you search Google trends for a term like “taylor+swift”, and set your timescale to “2004 to present”, you’ll get an interesting graph that does demonstrate the meteoric rise to stardom of the pop star.
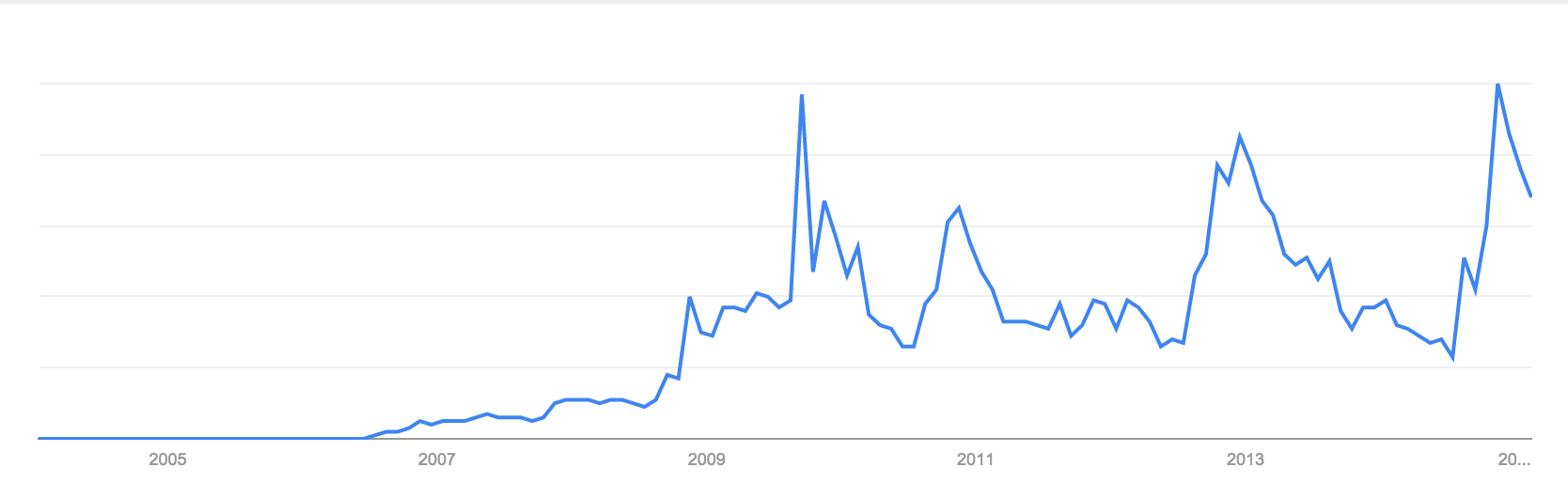
Google also gives you an option to download the data as a .CSV file; this is a great option if you want to compare trends in a more rigorous way than looking at their graphs side by side.
However there’s an issue with the timescales: if you download data from 2004 to present, Google will give you monthly or weekly data, but if you download data from June 2009, Google will give you daily data (unless it’s negligible).
I wrote a small script that searches Google trends for a certain term over a specified time frame, but does so over multiple small time intervals to obtain small time-scale data, and then stitches it all together using the full time scale for consistency.
Because Google offers the option of downloading the results of a search as a .CSV file, we don’t need any nasty scraping tools and can achieve everything in Python using just the webbrowser package (we will be using pandas later to join everything together and do some computations). We also define the directories we’ll be using.
import webbrowser
import time
import os
import shutil
import copy
import re
import csv
import pandas as pd
keyword = "taylor+swift"
path = '/Users/clintonboys/Downloads'
scrapings_dir = 'gt_{0}'.format(keyword)
if not os.path.exists(path+"/"+scrapings_dir):
os.makedirs(path+"/"+scrapings_dir)
The largest timeframe over which Google will reliably return daily data is two months (the period is probably 90 days but most three month periods are longer than this). So we start by defining a function to get the data for a particular two-month period simply by opening the relevant results.csv page with the webbrowser function; this will store the file in the /Downloads folder by default.
def ScrapeTwoMonths(keyword, year, startmonth):
print 'Scraping month'+str(startmonth)+' in '+str(year)
URL_start = "http://www.google.com/trends/trendsReport?&q="
URL_end = "&cmpt=q&content=1&export=1"
queries = keyword[0]
if len(keyword) > 1:
queries_list = []
for i in range(0,len(keyword)):
queries_list.append(keyword[i])
queries = '%20'.join(queries_list)
date = '&date='+str(startmonth)+'%2F'+str(year)+'%202m'
URL = URL_start+queries+date+URL_end
webbrowser.open(URL)
Now we define a function that gets all two-month data for a particular timespan, together with the weekly data over the whole timespan, and stores all the results files in a single folder (we sleep for a few seconds in between each call to ScrapeQuarter or the browser gets very confused).
def ScrapeRange(keyword, startmonth, startyear, endmonth, endyear):
for i in range(startmonth,11,2):
ScrapeTwoMonths(keyword,startyear,i)
time.sleep(7)
for y in range(startyear + 1, endyear):
for i in range(1,11,2):
ScrapeTwoMonths(keyword,y,i)
time.sleep(7)
for i in range(1,endmonth,2):
ScrapeTwoMonths(keyword,endyear,i)
time.sleep(7)
files = copy.deepcopy(os.listdir(path))
for i in range(0,len(files)):
if files[i].lower().endswith('.csv'):
try:
if files[i][-5] == ")":
oldname = path+'/'+files[i]
newname = path+'/report'+files[i][-6]+'.csv'
os.rename(oldname,newname)
except OSError:
pass
quarterly_files = [fn for fn in os.listdir(path) if fn.lower().startswith('report')]
for file in quarterly_files:
shutil.move(path+"/"+file,path+'/'+scrapings_dir)
full_path = path+'/'+scrapings_dir
newfiles = copy.deepcopy(os.listdir(full_path))
for i in range(0,len(newfiles)):
oldname = full_path+'/'+newfiles[i]
if os.path.getsize(oldname) < 800:
print 'File '+oldname+' is unusually small...'
newname = full_path+'/'+str(os.path.getmtime(full_path+'/'+newfiles[i]))[:-2]+".csv"
os.rename(oldname, newname)
Now we need pandas to join all the bimonthly files together into a single big pandas data frame. This is a bit fiddly because we have to chop all the irrelevant stuff off the csv files before pandas will read them properly. Use a bit of regular expressions because they’re cool.
def CreateDailyFrame():
files = copy.deepcopy(os.listdir(path+'/'+scrapings_dir))[:-1]
print files
date_pattern = re.compile('\d\d\d\d-\d\d-\d\d')
for i in range(0,len(files)):
if files[i].lower().endswith('.csv'):
oldname = path+'/'+scrapings_dir+'/'+files[i]
newname = path+'/'+scrapings_dir+'/'+'bimonthly'+str(i)+'.csv'
temp_file = csv.reader(open(oldname,'ru'))
with open(newname,'wb') as write_to:
write_data = csv.writer(write_to, delimiter=',')
for row in temp_file:
if len(row)==2:
if re.search(date_pattern,row[0]) is not None:
write_data.writerows([row])
os.remove(oldname)
files = [fn for fn in copy.deepcopy(os.listdir(path+'/'+scrapings_dir))[:-1] if fn.lower().startswith('bimonthly')]
frames_list = []
for file in files:
df = pd.read_csv(path+'/'+scrapings_dir+'/'+file,index_col=None,header=None)
list.append(df)
frame = pd.concat(list,ignore_index=True)
return frame
A similar function cleans up the weekly data and makes a pandas frame so everything is ready to be stitched together.
def CreateWeeklyFrame():
date_pattern = re.compile('\d\d\d\d-\d\d-\d\d\s-\s\d\d\d\d-\d\d-\d\d')
oldname = path+'/'+scrapings_dir+'/'+'weekly_data.csv'
newname = path+'/'+scrapings_dir+'/'+'weekly.csv'
temp_file = csv.reader(open(oldname,'ru'))
with open(newname,'wb') as write_to:
write_data = csv.writer(write_to, delimiter=',')
for row in temp_file:
if len(row) == 2:
if re.search(date_pattern,row[0]) is not None:
write_data.writerows([row])
os.remove(oldname)
frame = pd.read_csv(newname,index_col=None,header=None)
return frame
To stitch everything up, first we make the frames we need, using some regular expressions to break up the date ranges.
def StitchFrames():
daily_frame = CreateDailyFrame()
interim_weekly_frame = CreateWeeklyFrame()
daily_frame.columns = ['Date', 'Daily_Volume']
pd.to_datetime(daily_frame['Date'])
interim_weekly_frame.columns = ['Date_Range', 'Weekly_Volume']
date_pattern = re.compile('\d\d\d\d-\d\d-\d\d')
startdates = []
enddates = []
for i in range(0,len(interim_weekly_frame['Date_Range'])):
startdates.append(re.findall(date_pattern,interim_weekly_frame['Date_Range'][i])[0])
enddates.append(re.findall(date_pattern,interim_weekly_frame['Date_Range'][i])[1])
weekly_frame = pd.DataFrame(data=[startdates,enddates,interim_weekly_frame['Weekly_Volume'].tolist()]).transpose()
weekly_frame.columns = ['Start_Date', 'End_Date', 'Weekly_Volume']
pd.to_datetime(weekly_frame['Start_Date'])
pd.to_datetime(weekly_frame['End_Date'])
Now we define weekly date bins using pandas.
bins = []
for i in range(0,len(weekly_frame)):
bins.append(pd.date_range(weekly_frame['Start_Date'][i],periods=7,freq='d'))
weekly_frame = weekly_frame.set_index('Start_Date')
daily_frame = daily_frame.set_index('Date')
final_data = {}
We now stitch everything together, adjusting each individual week’s data so it is consistent with the start date’s measure from the long-timescale data.
for i in range(0,len(bins)):
for j in range(0,len(bins[i])):
final_data[bins[i][j]] = weekly_frame['Weekly_Volume'][str(bins[i][0].date())]*daily_frame['Daily_Volume'][str(bins[i][j].date())]/daily_frame['Daily_Volume'][str(bins[i][0].date())]
Finally we rescale everything again so it is consistent with Google’s 0-100 scale.
final_data_frame = DataFrame.from_dict(final_data,orient='index').sort()
final_data_frame[0] = np.round(final_data_frame[0]/final_data_frame[0].max()*100)
final_data_frame.columns=['Volume']
final_data_frame.index.names = ['Date']
final_name = path+'/'+scrapings_dir+'/'+'final_output.csv'
final_data_frame.to_csv(final_name, sep=',')
This code is available in a Github repo. There’s definitely room for a bunch of improvements but it does what I need it to do at the moment.
UPDATE (24/10/2016): Google has made significant changes to their Trends product which means this code no longer works. I’m working on updating it and will write a new post when this is done.
UPDATE 2 (18/2/2017): I have fixed the code so the trendy scraper is now working again. The updated code is in Github and there is a post on the blog. I made a few improvements along the way.